Azure Loadbalancer: The NAT device you didn't know you wanted

Most people think of Azure Public Load Balancer as that thing that spreads web traffic across multiple servers. Fair enough - that's what it does best. But it's actually a Swiss Army knife for network address translation that can solve some tricky connectivity problems you might not expect.
Let me show you what I mean.
The Load Balancer You Think You Know
Azure Public Load Balancer typically sits in front of your web servers, databases, or APIs. Traffic hits the load balancer's public IP, and it decides which backend server gets each request. Simple enough.
But here's where it gets interesting - that same load balancer can handle much more sophisticated network address translation scenarios; rather than assigning a public IP to each VM in a VNet you can create specific DNAT rules for inbound traffic with 1:1 port translation. You can also create specific SNAT rules for outbound rules based on address pools that mean you can go way above and beyond the 64000 port limit of a single IP.
Rule-Based NAT for Inbound Connections
Let's say you're running an environment with five different services, each on separate VMs. Normally, you'd need five public IP addresses - one for each service. That gets expensive fast.
Instead, I can use inbound NAT rules to share a single public IP across all services. Picture this setup:
- Web API via
20.1.2.3:8000→ VM1 port 80 - Admin panel via
20.1.2.3:8001→ VM2 port 443 - Database via
20.1.2.3:8002→ VM3 port 5432
Each service gets direct access whilst sharing the same public IP, but you can scale out with multiple public IPs if you want to add even more services behind a single loadbalancer.
Outbound NAT: The Fixed IP Pool Solution
Here's where things get really useful. Let me paint a scenario I've seen countless times.
You're running a service that needs to connect to external APIs - payment processors, third-party data feeds, whatever. These external services often require IP allowlisting for security. You need a fixed pool of IP addresses for your outbound connections.
Azure Firewall can do this, but it maxes out at around 2,500 SNAT ports per public IP. If you're running high-throughput applications or have many concurrent connections, you'll hit that limit quickly.
Load balancer outbound rules can solve this. With multiple public IPs, you can get around 64,000 SNAT ports per IP. That's a massive increase in capacity whilst maintaining your fixed IP pool for allowlisting. You don't get the level of layer 7 filtering you get with a firewall but you do get something that supports long lived TCP connections.
Here's the calculation that matters: if you have 1,000 concurrent connections that each last 30 seconds, plus the TCP TIME_WAIT period of 240 seconds, you need about 9,000 SNAT ports. Azure Firewall's 2,500 port limit won't cut it, but a single load balancer IP gives you more than 10 times that capacity.
Why Long-Lived Connections Love Load Balancers
Here's something I've tested extensively - Azure Public Load Balancer handles long-lived TCP connections really well. This is because it's built into the fabric of Azure networking and doesn't rely on a scale set of VMs in the same way things like App Gateway and Azure Firewall do. I've run connections through it that lasted over a week and the latency was consistent and reliable. This bridges the gap that I've been up against with internet facing services using legacy protocols that hold long connections and have slow reconnection times When VMs that live under the hood of may Azure constructs get updated, restarted, migrated across hosts, or replaced, your long-lived connections can get dropped.
My testing involved establishing TCP connections and sending periodic heartbeat messages every second. With Azure Firewall, connections would randomly drop after a while due to backend maintenance or scale out and scale in. With Azure Public load balancers, the same test consistently ran for over a week without interruption.
Real-World Limitations You Need to Know
There are some limitations to Azure Public Loadbalancers. The good news is that while things like Azure Firewall have their own dedicated subnet of which only 1 can exist in a vNet, loadbalancers can be scaled out sideways to 1000.
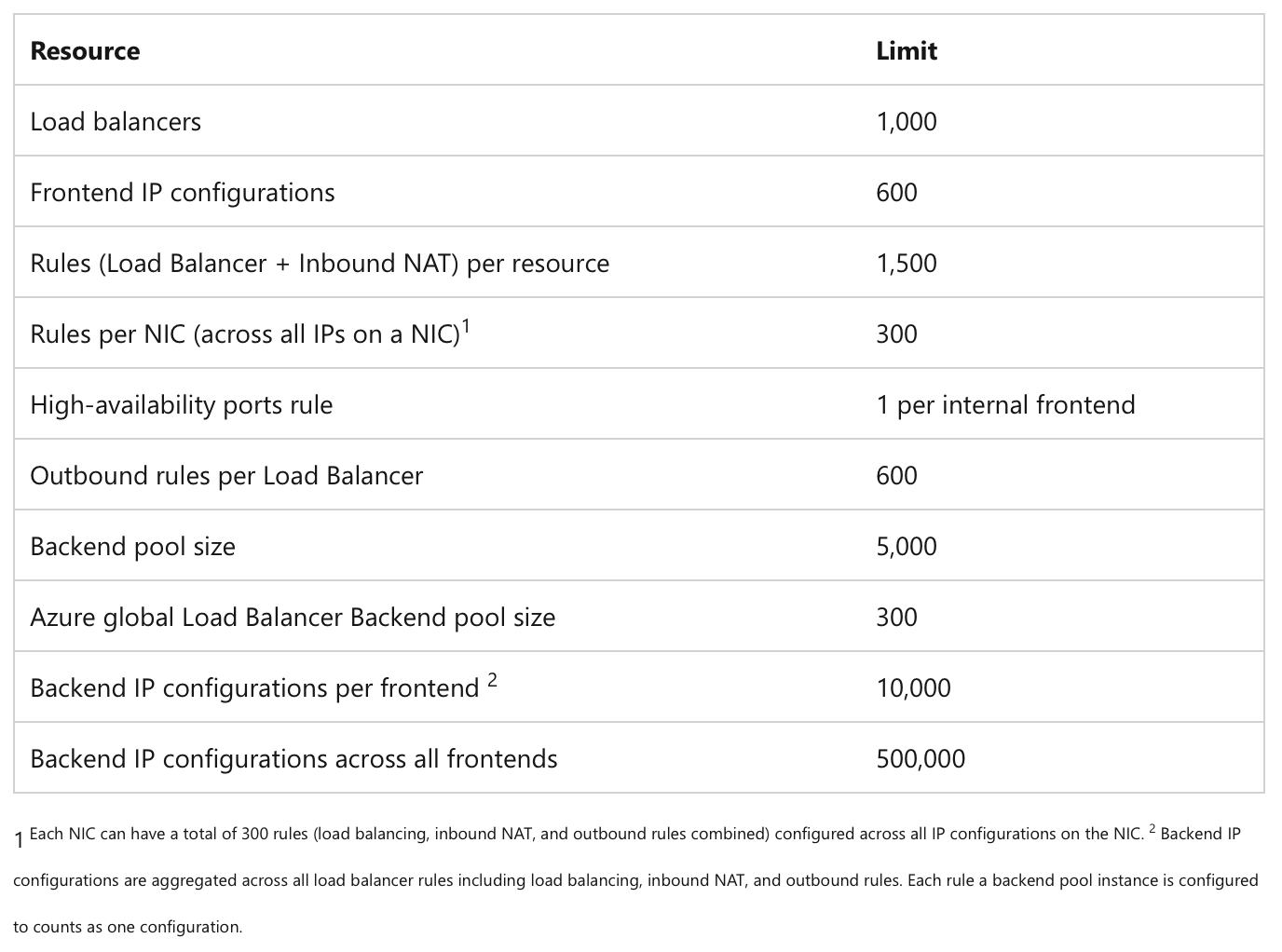
Rules Per Load Balancer: You can have up to 1,500 total rules per load balancer (this includes both load balancing rules and inbound NAT rules combined). If you're doing microservices with lots of individual endpoints, you might hit this faster than expected.
Frontend IP Configurations: 600 IP configurations means that if you were using it for inbound only you could associate 600 PIPs to it and have a couple of ports per IP mapped to different web services.
Outbound Rules: Limited to 600 outbound rules per load balancer, which should be more than enough for most scenarios.
Port Range Conflicts: Inbound NAT rules can't overlap with load balancing rules on the same frontend IP and port. You need to plan your port allocations carefully.
Here's the bit that catches people out - SNAT port allocation isn't automatic. If you don't configure outbound rules explicitly, Azure gives you a default allocation that's often too small:
- 50 or fewer VMs: 1,024 ports per instance
- 51-100 VMs: 512 ports per instance
- 101-200 VMs: 256 ports per instance
- 201-400 VMs: 128 ports per instance
- 401-800 VMs: 64 ports per instance
- 800+ VMs: 32 ports per instance
So if you have 200 VMs, each only gets 256 SNAT ports by default. That's why explicit outbound rules matter - you can allocate 10,000+ ports per VM if needed.
The maths works in your favour though: with 600 possible frontend IPs and 64,000 SNAT ports per IP, you could theoretically have over 38 million SNAT ports available. In practice, you'll hit other limits (like cost) long before you max out the port capacity.
Performance testing for long lived TCP connections
You'll probably be familiar with the echo test methodology I have been using to validate long lived TCP across cloud networks. The headline figures are below and show that for the 118 hour test I did the latency was pretty consistent.
--- Echo Client Statistics ---
2025-06-08 20:44:17.514 - INFO - Packets: Sent = 425206,
Received = 425206,
Lost = 0 (0.0% loss)
2025-06-08 20:44:17.794 - INFO - RTT: Min = 868.971μs,
Max = 206553.369μs,
Avg = 1587.804μs
2025-06-08 20:44:18.531 - INFO - StdDev = 751.036μs
2025-06-08 20:44:18.531 - INFO - Connection closed
2025-06-08 20:44:18.531 - INFO - Echo client terminated
The max latency was a biscuit over 200ms this is consistent with the exterme outlier found on the control, which was to the same VM with no loadbalancer.
Key outlying latency findings:
Extreme outliers:
- Test: 206,553 μs peak (packet #53,578)
- Control: 208,203 μs peak (packet #79,465)
Outlier rates:
- Test: 1.69% packets beyond 3σ (7,196 outliers)
- Control: 1.32% packets beyond 3σ (5,609 outliers)
Performance comparison: Control performed better with 3.3% lower average latency (1,535 vs 1,588 μs) and more consistent performance. Both tests show scattered extreme outliers throughout their ~5-day test periods rather than clustered spikes.